Hi all,
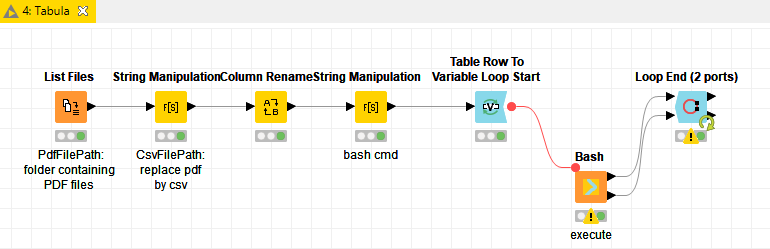
I followed Philipp’s suggestion and implemented a solution with Tabula, which I wanted to share with the community.
Basically, I am parsing a command string and executing it with the bash node.
Parse with string manipulation node:string("java -jar \"C:\\Users\\Veys\\Desktop\\Tabula\\jar\\tabula-1.0.3-jar-with-dependencies.jar\" \"") + string($PdfFilePath$) + string("\" --no-spreadsheet --stream --pages all --area 338.19,18.997,645.501,573.346 --outfile \"") + string($CsvFilePath$) + string("\"")
Result:java -jar “C:\Users\Veys\Desktop\Tabula\jar\tabula-1.0.3-jar-with-dependencies.jar” “C:\Users\Veys\Desktop\Tabula\data\pdf\0795602.pdf” --no-spreadsheet --stream --pages all --area 338.19,18.997,645.501,573.346 --outfile “C:\Users\Veys\Desktop\Tabula\data\csv\0795602.csv”
Hope it helps 
 Tabula_2020-04-11_21h09_16770×249 12.6 KB
Tabula_2020-04-11_21h09_16770×249 12.6 KB